
拥塞控制的目的:
拥塞控制的目标是最大化利用网络链路的带宽,同时防止过多数据注入网络中,让路由或链路过载; 不让网络链路太堵,也是为了降低大家的网络时延,这里的时延就是从 数据发送出去,到目的地后返回,最后收到一个响应 所花的时间。 网络不卡了,大家才用得开心,用户体验才能上去。

拥塞控制带来的不便
很多大众用户在公共场所里,机场wifi 和 会议场馆中的网络通畅经常很糟糕。 对于一些科学家,气候科学研究人员,天体物理学家,全球的防疫研究人员,通常需要和全世界的同行一起合作,交换千万亿字节的数据。但是在跨国距离的网络传输里面,网速慢太慢了,数据只有 几 M bps的传输速度。 这个问题来自于 需要改进的TCP拥塞控制策略。
带宽利用率不高,他这种用赛控制非常保守,唯唯诺诺。
标准TCP 的问题
1980年提出的传统TCP拥塞控制算法在大家学生时期里学校就教过,在校招面试中也经常出现。 慢开始,拥塞避免,快重传,快恢复。 教材中这个经典的拥塞控制策略的关键方法是,监测到丢包就认为发生了拥塞。也称为”基于丢包的拥塞控制算法“ 这个方法在当时是比较合理的方法,但当时的网络环境和现在有很多不同。网络宽带从 Mbps 变成了现在的 Gbps, 内存芯片从当时的 KB 变成了现在的GB。小时后家里的电脑,512KB的内存芯片都用了好几年的时间。
-
网络环境中,丢包 和 拥塞的 直接关系变得比过去小很多了,直接把丢包看作拥塞的信号不太合适。 事实上,网络中存在很多传输错误导致的丢包,基于丢包的拥塞控制算法不能区分他们。 标准TCP要能正常工作,那么错误丢包率需要足够小。 在 又长又宽的长肥管道,就是指迟延高,带宽大的一条网路链路,因为错误丢包率没办法足够小,所以发送方的拥塞窗口会收敛到一个很小的值。这就是为什么明明客户端和服务器都有很大的带宽,运营商的网络也没被占满,但下载速度还是不忍直视。
-
其次,网络中的buffer缓冲区,类似于我们输液时输液管中间膨大的一部分,在网络里用来吸收一些流量波动。 TCP连接开始阶段,buffer倾向于被占满,瓶颈链路上的缓冲区比较大时,拥塞控制会填满buffer导致缓冲区膨胀,增加迟延。 buffer容量很小时,缓冲区很快就被填满而丢包,最终产生一个很小的网络吞吐量。
如何优化,关键点是什么
要想找到替代方案,需要思考一个Where and How的问题。要理解,网络拥塞是从哪里来的,是如何产生的?
网络拥塞和瓶颈的联系很大,瓶颈就是 最慢的那一截网络链路。非常重要
-
决定了连接整个链路最大的数据交付率。就像木桶效应里面,能装多少水是有最短的那片木头决定的
-
那些一直无法消失的buffer 队列 就位于瓶颈部分,瓶颈部分的等待发送队列消失了,整个网络链路的buffer就空了。
网络链路像一条水管,要想用满这条水管,最好的办法就是给这根水管灌满水。 能灌满水的水量 = 水管粗细 * 水管长度。
那么正在网络上进行传播的数据包数量 or 能容纳的数据包数量 = 链路带宽 * 往返延迟: 带宽和延迟的乘积就是发送窗口应有的大小
TCP网络上的关键约束
对TCP来说, 不管网络链路怎么玩玩绕绕,就算途径俄罗斯,跨越喜马拉雅,再复杂的路线,TCP都把他当作 一截链路,上面有两个重要的约束。 TCP的做法是直接估计水管容量,而BBR算法 是:
- 分别估计带宽和延迟,而不是估计水管的容积。
- 且因为不容易区分 拥塞丢包和错误丢包,所以干脆不考虑丢包。
发送窗口等于两者相乘, 把这个结果表示的数据包数量称作 BDP(bindwidth delay product)
如何估计BtlBw 和 RTprop
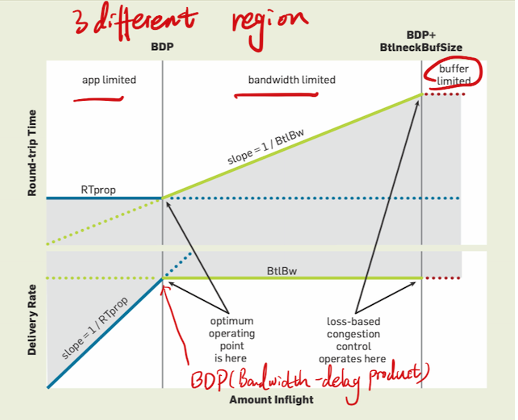
瓶颈带宽和 传播迟延很难同时测量出来, 因为两者出现在 BDP的两侧 要测量带宽,就要把水管填满,缓冲区里就有一定量的数据包队列,此时迟延比较高;要测量最低迟延,就要保证缓冲区为空,
- 交替测量,极大值和极小值作为估计
因为TCP 没有机制来跟踪瓶颈带宽,BBR是根据收到的确认包计算出的平均交付率来,用一段时间窗口内最大的平均交付率来对 瓶颈带宽做一个无偏估计。
BBR的启动阶段,通过确认包发现有效带宽不再增长了,就会进入拥塞避免阶段。BBR会在 bandwidth limited 区间内停止增长,而基于丢包的标准TCP会在 buffer limited 区间停下。
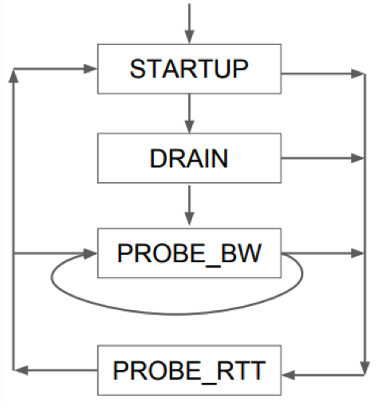
BBR的4个阶段
当宽带降低一半的时候,多出来的数据包占用了 buffer,导致RTT延迟显著增加,这时候确认包的平均交付率会降低,之后估计出来的带宽也降低一半,发送端窗口甚至无法发包,buffer被排空。
当带宽增加一倍时,BBR 仅用 1.5 秒就收敛了;而当带宽降低一半时,BBR 需要 4 秒才能收敛
延迟探测阶段
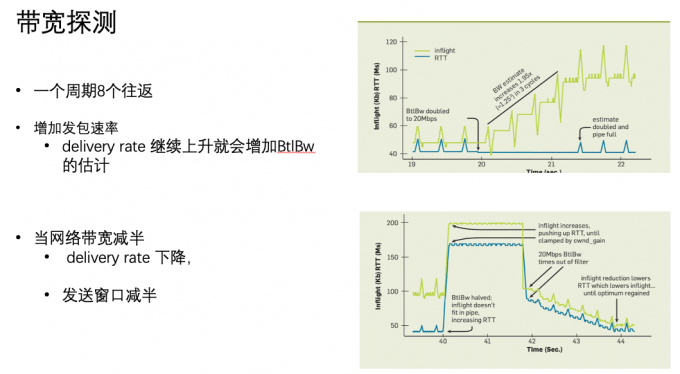
BBR 每过10秒 进行一侧延迟探测,以一个极低的速率发包。这段时间发送窗口固定为4个包,持续200毫秒。也就是大约2%的时间测量延迟。
BBR实验效果
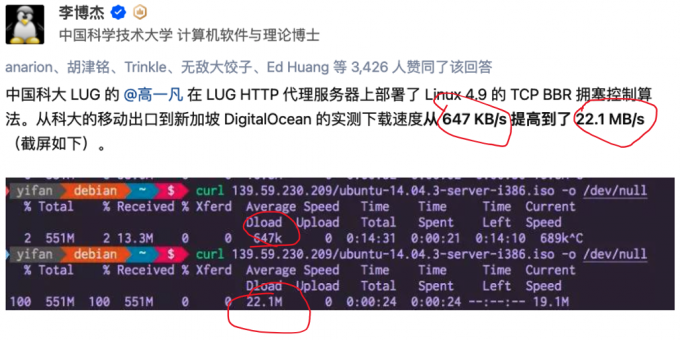
解决的2个问题
1. 在有一定丢包率的网络链路上充分利用带宽,非常时候长肥管道,高延迟高带宽的网络链路。
2. 降低网络链路上buffer占用率,降低延迟。
🤔 BBR对于“基于丢包的一系列拥塞控制算法”不公平。就像大家都在用冷兵器,但是一小步人确有了机枪。
如何部署BBR
-
拥塞控制算法是,让数据发送端决定数据发送窗口。哪边发送的数据有效,就在哪边部署BBR
-
需要编译系统内核
linux内核从4.9版本开始就加入了bbr协议,如果系统linux内核版本大于4.9,就可以直接启动bbr功能。
查看内核系统版本:
➜ cat /proc/version
Linux version 5.4.0-42-generic (buildd@lgw01-amd64-023) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) #46~18.04.1-Ubuntu SMP Fri Jul 10 07:21:24 UTC 2020
(base)
修改系统变量
sudo vim /etc/sysctl.conf
在末尾加上
net.core.default_qdisc=fq
net.ipv4.tcp_congestion_control=bbr
使配置生效
➜ sudo sysctl -p
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr
查看是否生效
# /etc [14:56:49]
➜ sysctl net.ipv4.tcp_available_congestion_control
net.ipv4.tcp_available_congestion_control = reno cubic bbr
# /etc [14:58:50]
➜ sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = bbr
验证是否启动
# ~ [14:59:59]
➜ lsmod | grep bbr
tcp_bbr 20480 9
下载一个数据集,测试一下下载网速:
参考
知乎回答:Linux Kernel 4.9 中的 BBR 算法与之前的 TCP 拥塞控制相比有什么优势? BBR: Congestion-Based Congestion Control